How the Model Works#
OpenAg is composed of two separate models for irrigated and nonirrigated lands. Each of these models operates on distinct Model Areas, which provide the suite of inputs, region definitions, crop data, and more required to run OpenAg’s models. This section provides information on how the models in OpenAg work and the Model Areas that they work with.
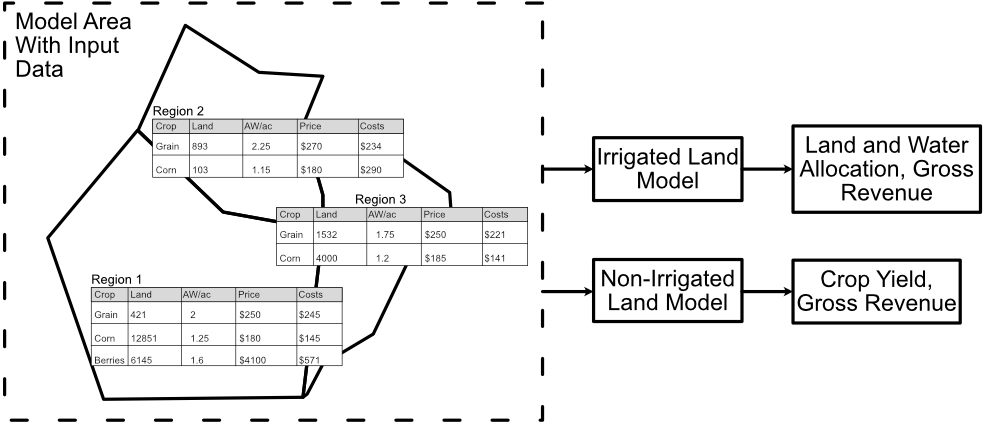
Fig. 1 A diagram of OpenAg’s input data and model relationships. Each model area has many regions with independent data. Each region runs as an independent model, but OpenAg runs all regions through both models simultaneously.#
Each model area in OpenAg contains many regions with their own data (Fig. 1) for
What crops are grown there,
How much it costs to grow them,
Applied Water (AW), or irrigated water, used in growing them,
Expected prices and yields,
And more.
OpenAg runs each region as an independent model, with their own input data and results. Regions with irrigated land will utilize OpenAg’s irrigated land crop choice model to estimate land use decisions and regions with nonirrigated crops will also utilize OpenAg’s statistical regression model to estimate yields based on seasonal rainfall.
Please see the following articles for additional details on how these models work.
Contents
- Models Available in OpenAg
- Modeled Areas in OpenAg
- Model Input Data
- The Irrigated Land Crop Choice Model
- The Nonirrigated Lands Regression Model
- Simple Modeling and Linear Scaling
- Model Outputs
- Model Limitations
- Explanation and Limitations of Net Revenue Estimates
- How OpenAg Splits Data Between Irrigated and Nonirrigated Lands